مقدمه
من و یاشار شاهینزاده در راستای برنامهی باگبانتی کافهبازار آسیبپذیریهای امنیتی مختلفی را شناسایی کردیم. در یکی از آسیبپذیریها، وجود یک مشکل رمزنگاری به دور زدن فرایند احراز هویت (Authentication bypass) در وباپلیکیشن کافهبازار منجر میشد. آسیبپذیری مذکور به سرعت برطرف و 15 میلیون تومان بانتی به آن اختصاص داده شد. در این نوشتار به جزئیات این آسیبپذیری میپردازیم. این مطلب پیشتر در وبلاگ باگبانتی کافهبازار منتشر شده است:
جزئیات فنی
اگر احراز هویت (Authentication) به شکل نامناسبی انجام شود، ممکن است یک مهاجم به عنوان کاربر معتبر شناسایی شده و دسترسی بگیرد. نتیجهی این دسترسی، از بین رفتن محرمانگی، یکپارچگی یا دسترسپذیری اطلاعات خواهد بود. بنابراین، بررسی فرایند احراز هویت و حصول اطمینان از صحت کارکرد آن، یکی از مهمترین موارد در ارزیابی امنیتی یک اپلیکیشن، سرویس یا دستگاه میباشد.
وباپلیکیشن کافهبازار، به کاربر اجازه میدهد که با استفاده از شمارهی تلفن یا آدرس ایمیل به حساب خود دسترسی داشته باشد.

برای احراز هویت با استفاده از شمارهی تلفن، یک عدد چهار رقمی به عنوان کد احراز هویت به آن ارسال میشود. پس از وارد کردن کد دریافت شده، درخواست زیر به سرور ارسال میشود:
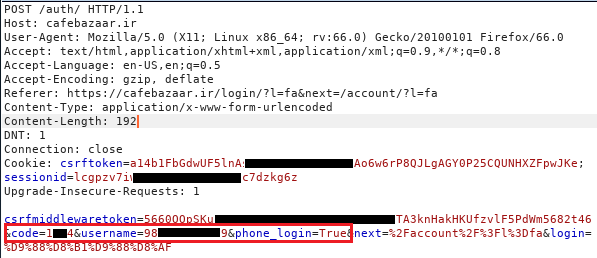
code: کد وارد شده
phone_login=True: احراز هویت با شمارهی تلفن انجام شود.
اگر شمارهی تلفن و کد وارد شده مطابقت داشته باشند و درخواست معتبر باشد، سرور به شکل زیر پاسخ میدهد و کاربر وارد حساب خود میشود:

در صورتی که اطلاعات ارسالی نامعتبر باشد، سرور با کد های وضعیت 200،403 و سایر کدها پاسخ میدهد.
اگر فاکتورهای محدودکننده برای جلوگیری از حملهی Brute-force به خوبی اعمال نشده باشند، امکان حدس مقدار کد وجود دارد. در مورد فاکتورهای محدودکننده چنین نتیجهگیری میکنیم:
- با توجه به این که کد یک عدد چهار رقمی است، در کل 10,000 حالت برای آن ممکن است که تعداد حالت کمی است.
- مدت زمان اعتبار کد 20 دقیقه است.
- پس از ورود، کد منقضی نمیشود و میتوان دوباره از آن استفاده کرد، بنابراین یکبار مصرف (OTP) نیست.
- تعداد تلاش برای ورود، به یک برای هر شناسهی کاربری (شماره یا آدرس ایمیل) محدود شدهاست و برای تلاشهای بعدی نیاز به تایید Captcha است، پس به طرز موثری جلوی حمله برای حدس زدن توکن گرفته شده است.البته با توجه به نتایج بالا، امکان دور زدن Captcha و اجرای حملهی Brute-force با استفاده از عامل انسانی وجود دارد. روشی پرهزینه که توسط مجرمان سایبری و اسپمرها استفاده میشود، به این شکل که Captcha را از سایت هدف بارگیری کرده و سپس آن را در سایتهای تقلبی با موضوع گیم یا پورن نمایش میدهند تا کاربران آن سایت Captcha را حل کنند!

در احراز هویت با استفاده از آدرس ایمیل، یک ایمیل مشابه شکل زیر به کاربر ارسال میشود:
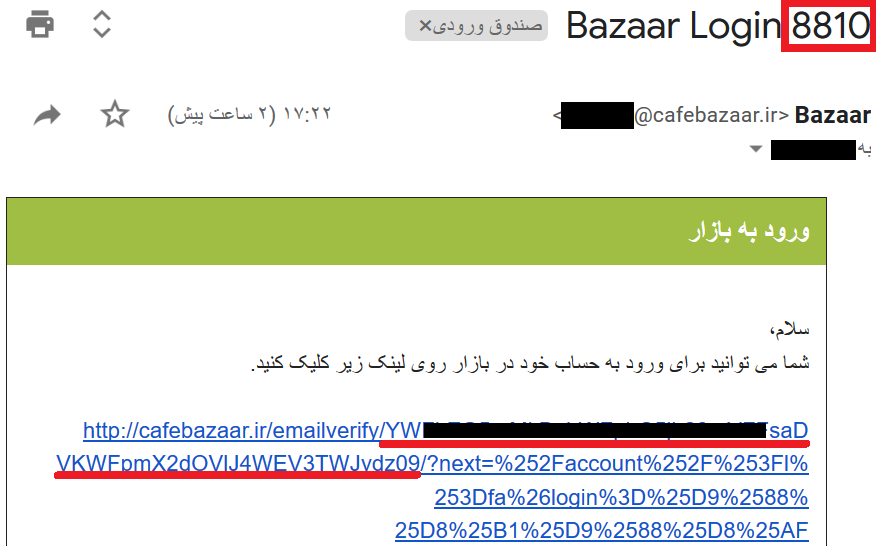
اگر قبلاً حسابی با آدرس ایمیل وارد شده ساخته نشده باشد، ایمیل ثبتنام ارسال میشود:
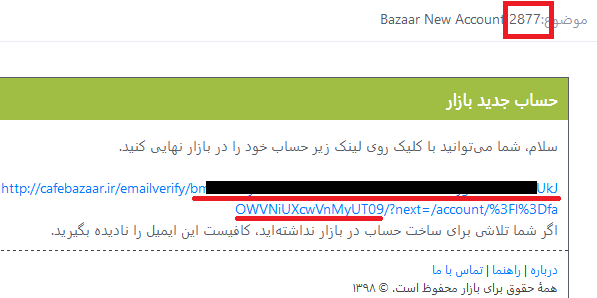
ایمیل ثبت نام و ایمیل ورود مشابه هستند. یک کد چهار رقمی در عنوان ایمیل و یک لینک در متن آن وجود دارد، برای ورود از طریق اپلیکیشن اندروید کد چهار رقمی را وارد می کنیم و برای ورود به حساب با مرورگر، لینک ارسالی را باز میکنیم. آدرس لینک ورود به این شکل است:
http://cafebazaar.ir/emailverify/dXNlckBnbWFpbC5jb20mOW5nb0Y5VGQzNVpadWxrOG5yRFF3QT09/?next=/account/%3Fl%3Dfaقسمت مهم در آدرس بالا، مقدار زیر است که احراز هویت با استفاده از آن انجام میشود:
dXNlckBnbWFpbC5jb20mOW5nb0Y5VGQzNVpadWxrOG5yRFF3QT09مقدار بالا با base64 کد شده است، اگر آن را دیکد کنیم مقدار زیر حاصل میشود:
[email protected]&9ngoF9Td35ZZulk8nrDQwA==قسمت اول، برابر با آدرس ایمیل کاربر است و قسمت دوم یک مقدار base64 دیگر است که به عنوان توکن احراز هویت در لینک ورود استفاده شده است. اگر قسمت دوم را دیکد کنیم مقدار زیر حاصل میشود:
\xf6\x78\x28\x17\xd4\xdd\xdf\x96\x59\xba\x59\x3c\x9e\xb0\xd0\xc0این قسمت دارای طول 16 بایت است و مقدار نامفهومی دارد، در مورد این مقدار حالت های زیر محتمل است:
- داده با طول 16 بایت، در بعضی از توابع رمزنگاری یا هش معمول است. به عنوان مثال، طول هش MD5 برابر 16 بایت است. ممکن است مقدار بالا حاصل یک تابع از این نوع باشد.
- ممکن است این مقدار با استفاده از یک الگوریتم کد شده باشد و به سادگی بتوان آن را به مقدار اولیه برگرداند (مثلاً خروجی یک الگوریتم فشردهسازی باشد). بررسی این حالت نتیجهای نداشت.
- ممکن است این مقدار (شبه) تصادفی باشد. دوباره، در این صورت ممکن است مقدار (شبه) تصادفی به روش ناامنی تولید شده باشد.
تا این جا، میتوانیم الگوی تولید مقدار لینک ورود را به شکل شبهکد زیر نشان دهیم:
function GenerateLoginLink(email_address, ...) {
link_format = "http://cafebazaar.ir/emailverify/%s/?next=/account/%3Fl%3Dfa"
link_token = GenerateLinkToken(...)
return link_format.format( Base64Encode( email_address + "&" + link_token ) )
}قسمت توکن در لینک ورود برای ما اهمیت بیشتری دارد، اگر بتوانیم الگوریتم تولید این مقدار (تابع GenerateLinkToken) را کشف کنیم و قادر به بازتولید آن باشیم، خواهیم توانست لینک ورود را برای آدرس ایمیل دلخواه تولید کنیم و فرایند احراز هویت را دور بزنیم. بنابراین، لازم است توکنهای تولید شده را تحلیل کنیم.
نکته: از ابزار Burp Sequencer در نرمافزار BurpSuite میتوان برای اجرای برخی تحلیلها بر روی توکن استفاده کرد.
تحلیل توکنها
ممکن است فاکتورهای مختلفی در تولید توکن لینک موثر باشند. متغییرهایی مثل آدرس ایمیل، کد چهار رقمی، زمان و یا مقادیر ثابت ممکن است از جملهی این فاکتورها باشند. پس، میتوانیم تابع تولید توکن لینک را با شبهکد زیر نشان دهیم:
function GenerateLinkToken(email_address[?], four_digit_code[?], time[?], other_variables[?], constants[?]) {
...
return Base64Encode(...)
}برای بررسی این فاکتورهای احتمالی، نیاز به نمونههای آماری از اطلاعات ایمیل ورود (آدرس ایمیل، کد چهار رقمی، توکن لینک و زمان ارسال ایمیل) داریم تا بتوانیم تاثیر این فاکتورها را بررسی کنیم. برای جمعآوری اعضا، لازم است که تعداد قابل توجهی ایمیل ورود دریافت کنیم، اما دو محدودیت وجود دارد:
- با یک آدرس ایمیل، تنها چند ایمیل از سمت سرور میتوانیم دریافت کنیم و پس از رسیدن به حداکثر تعداد، درخواستهای بیشتر برای ارسال ایمیل رد میشوند.
- در مدت کوتاه، ایمیلهای ارسالی به یک آدرس، مشابه هستند، در حالی که ما مقادیر متفاوت را برای بررسی تغییرات لازم داریم.
برای دور زدن این دو محدودیت، میتوانیم از دو روش استفاده کنیم:
- یک سرور ایمیل (SMTP) را به نحوی پیکربندی کنیم که تعداد نامحدودی آدرس ایمیل در اختیار داشته باشیم.
- از سرویسهای آنلاین دریافت ایمیل انبوه استفاده کنیم.
نکته: از ابزار Burp Collaborator در نرمافزار BurpSuite میتوان برای دریافت ایمیل از طریق پروتکل SMTP استفاده کرد.
پس از جمعآوری نمونهها و بررسی آنها نتایج زیر حاصل شد:
- کد چهار رقمی که در عنوان ایمیل وجود دارد، به شکل تقریباً یکنواخت توزیع شده است. بنابراین، این کد یک متغییر تصادفی در بازهی 0000 تا 9999 است.
- طول توکن لینک همواره برابر با 16 بایت است.
- در بررسی نمونههای با کد چهار رقمی یکسان و آدرس ایمیل متفاوت، مثل نمونههای زیر:
email_address, four_digit_code, link_token, time [email protected], 1398, NlFDI49KAiGGe4y8yBLz5Q==, t1 [email protected], 1398, NlFDI49KAiGGe4y8yBLz5Q==, t2 [email protected], 1398, NlFDI49KAiGGe4y8yBLz5Q==, t3 [email protected], 1398, NlFDI49KAiGGe4y8yBLz5Q==, t4
مشخص میشود که آدرس ایمیل و زمان درخواست، تاثیری در توکن لینک ندارند و تنها فاکتوری که بر مقدار آن اثر میگذارد، کد چهار رقمی است. ممکن است فاکتورهای دیگری هم لحاظ شده باشند، اما چون تنها با تغییر کد چهار رقمی مقدار توکن لینک تغییر میکند، این فاکتورها ثابت هستند و یا رفتار ثابتی دارند. بنابراین، میتوانیم از آنها صرفنظر کنیم.
طبق نتیجهگیریهای بالا، تابع تولید توکن لینک را میتوانیم با شبهکد زیر نشان دهیم:
function GenerateLinkToken(four_digit_code = Random(0000, 9999)) {
...
return Base64Encode(...)
}اگر تابع Func1 با رفتار غیرتصادفی موجود باشد و ما تمام مقادیر ورودی و تمام مقادیر برگشتی نظیر آنها را داشته باشیم، بدون این که از الگوی تابع Func1 خبر داشته باشیم، میتوانیم تابع Func2 را بسازیم که از نظر نتیجه با تابع اول برابر باشد:
Func1(X) == Y
x1 -> y1, x2 -> y2, x3 -> y3, ... , xN -> yN
Func2(X) == | x1 y1
| ... ...
| xN yN
Func1(X) == Func2(X)با توجه به رابطهی بالا، اگر ما بتوانیم مقدار توکن لینک را به ازای هر کد چهار رقمی به دست آوریم، میتوانیم تابعی مشابه GenerateLinkToken بسازیم که از آن در سمت سرور برای تولید توکن لینک استفاده شده است.
برای پیدا کردن مقدار توکن لینک برای هر یک از 10،000 کد چهار رقمی، لازم است تعداد زیادی ایمیل ورود دریافت کنیم. در مورد تعداد ایمیلها این نکته مهم است:
به طور متوسط، حداقل تعداد ایمیل لازم برای استخراج تمام 10،000 مقدار ممکن برای توکن لینک به شکل زیر قابل محاسبه است:9999
Σ 10^4 / (10^4 – n) ≃ 97876
n = 0
با استخراج هر دادهی خاص، احتمال تکراری بودن دادههای بعدی افزایش پیدا میکند. در نهایت، احتمال پیدا کردن دادهی خاص به صفر میل میکند. بنابراین، برای استخراج بخش کوچکی از 10،000 حالت موجود نیاز به ارسال درخواستهای زیادی است و از آن ها صرفنظر میکنیم.
نتیجهی جمعآوری ایمیل ها به شکل زیر بود:
- تعداد 34،500 ایمیل دریافت شد که فقط 9،700 (28 درصد) از آن شامل دادههای خاص بود و بقیه دادهها تکراری بودند.
- 97 درصد کل حالتهای ممکن برای یک توکن لینک، یعنی 9،700 از 10،000 حالت ممکن به دست آمد، از 3 درصد کل حالتها، یعنی 300 عدد صرف نظر شد.
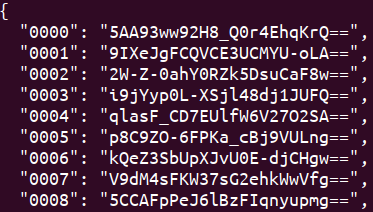
- اطلاعات به دست آمده (کدهای چهار رقمی و توکن لینک نظیر آنها) در فرمت JSON ذخیره شد.
اکسپلویت
با استفاده از اطلاعات ذخیره شده در فایل JSON، تابعی میسازیم که میتواند توکنهای لینک را بر اساس کد چهار رقمی تولید کند. این تابع 97 درصد مشابه تابع سمت سرور است و تنها 3 درصد احتمال دارد که نتواند توکن لینک را تولید کند. اکنون، میتوانیم لینکهای ورود ممکن برای یک آدرس ایمیل دلخواه را نیز تولید کنیم! اسکریپت پایتون استفاده شده برای تولید لینکهای ورود در این آدرس قرار دارد.

تعداد کل حالات لینک ورود برای یک آدرس ایمیل برابر 10،000 است که ما قادر به تولید 9،700 حالت هستیم. بر خلاف محدودیت Captcha در ورود با شمارهی تلفن، هیچ محدودیتی در تست لینک ورود وجود ندارد. بنابراین، میتوان با حملهی Brute-force لینک ورود ارسال شده به آدرس ایمیل دلخواه را در مدت زمانی کوتاه حدس زد. مراحل زیر را برای اجرای این جمله طی میکنیم:
- ابتدا درخواستی به وباپلیکیشین کافهبازار ارسال میکنیم تا یک لینک ورود به آدرس ایمیل کاربر قربانی ارسال شود.
- پس از تولید لینک و ارسال آن به قربانی، اکنون نوبت حدس زدن آن است. لینکهای ورود برای آدرس ایمیل کاربر را تولید و تست میکنیم.
- اگر حمله موفق باشد، به عنوان قربانی احراز هویت میشویم و اگر حمله شکست خورد (احتمال 3 درصد)، مدتی صبر میکنیم تا توکن منقضی شود و مراحل را تکرار میکنیم.
در شکل، مشخص است که پس از حملهی موفقیتآمیز، وارد حساب کاربری با آدرس ایمیل زیر شدهایم:
███████@cafebazaar.ir

علت ریشهای آسیبپذیری
به نظر میرسد سرور از یک الگوریتم رمزنگاری کلید متقارن برای تولید توکن لینک استفاده کرده است. مراحل زیر برای تولید توکن لینک متصور است:
- در بازهی 0000 تا 9999 یک عدد تصادفی به عنوان کد چهار رقمی انتخاب میشود.
- این عدد که اندازهاش برابر 4 بایت است (plaintext)، با استفاده از کلید رمز شده و مقداری 16 بایتی (ciphertext) حاصل میشود که همان توکن لینک است.
- توکن لینک در لینک ورود قرار داده شده و به آدرس ایمیل کاربر ارسال میشود.
- با باز کردن لینک ورود توسط کاربر، سرور توکن ساخته شده را دریافت کرده و آن را با استفاده از کلید رمزگشایی می کند تا کد چهار رقمی حاصل شود. در نهایت، کد چهار رقمی و آدرس ایمیل کاربر برای احراز هویت تطبیق داده میشوند.
هدف استفاده از رمزنگاری متقارن تضمین این موضوع بوده که تنها سرور بتواند لینک ورود را تولید و یا اطلاعات آن را استخراج کند. با توجه به این که طول توکن لینک (ciphertext) برای هر کد چهار رقمی (plaintext) همواره ثابت و برابر 16 بایت است و طول بلوک الگوریتم AES نیز به همین اندازه است، احتمالاً از این الگوریتم در حالت ECB برای رمزنگاری استفاده شده است. در این الگوریتم، اگر کلید و plaintext ثابت باشند، ciphertext نیز ثابت خواهد بود. به همین دلیل ما توانستیم بدون اطلاع از مقدار کلید و با پیدا کردن مقادیر نظیر plaintext و ciphertext رمزنگاری اعمال شده را بشکنیم.
برای برطرف کردن این مشکل، لازم است مقداری همواره تصادفی در رمزنگاری اعمال شود تا به ازای کلید و plaintext ثابت، ciphertext همواره تصادفی باشد. نتیجه این است که مهاجم قادر به شناسایی پترنها نخواهد بود. این مقدار تصادفی Initialization Vector (به اختصار IV) نامیده میشود و معمولاً طول آن برابر بلوک الگوریتم (16 برای AES) است.
صرفاً اعمال IV مشکل Brute-force را حل نمیکند، چون مهاجم میتواند با آزمون و خطا مقادیر نظیر را پیدا کند. برای جلوگیری از این مشکل، میتوان یک مقدار تصادفی مختص هر کاربر را در تولید توکن دخالت داد تا تمام توکنهای تولید شده مختص همان کاربر باشد.
آسیبپذیری بحرانی ZeroLogon که اخیراً جزئیات آن منتشر شد، منجر به حملهی تشدید دسترسی (Privilege Escalation) در سطح شبکههای ویندوزی میشود. علت ریشهای آسیبپذیری، این است که مقدار IV استفاده شده در الگوریتم AES-CFB همواره ثابت و برابر 16 بایت Null در نظر گرفته شده بود. در مورد آسیبپذیری مذکور، در این صفحه میتوانید بیشتر بخوانید.
پینوشت: این تحلیل به شکل Black-box ارائه میشود و محتملترین حالت بررسی شده است. حالتهای دیگری نیز متصور میباشد.
نکاتی برای بهبود Brute-force تحت وب
در زمینهی امنیت وب، Brute-force در مواردی مثل کشف نقاط ورودی و پارامترها، فازینگ و یا اکسپلویت آسیبپذیریها کاربرد دارد. این روش معمولاً پرهزینه است، یعنی نیازمند صرف زمان، توان پردازشی یا ترافیک زیاد است و با این وجود، ممکن است نتیجهای نداشته باشد. بنابراین، سعی میکنیم تا حد ممکن با هزینهی کمتر به نتیجهی بهتری برسیم. رعایت نکات زیر ممکن است در بهبود استفاده از این روش مفید باشد:
- Brute-force هوشمندانه
بهتر است انتخاب گزینهها بر اساس شرایط موجود صورت بگیرد تا از صرف هزینه برای گزینههای نامناسب جلوگیری شود. همچنین، در برخی موارد با دلایل منطقی میتوان مسئله را به شکل سادهتری باز تعریف کرد تا با هزینهی کمتری به حالت مطلوب رسید. در مثالی که ذکر شد، توکن با طول 16 بایت فضای بسیار بزرگی (16^256) داشت و انجام Brute-force عملی نبود اما با تحلیل توکن توانستیم این فضا را به 10،000 محدود کنیم. - استفاده از ابزارهای بهینه
در توسعهی برخی ابزارها برای Brute-force تحت وب، بهینه بودن آنها برای جلوگیری از اتلاف منابع مورد توجه بوده است. به عنوان مقایسه، ابزار ffuf نسبت به wfuzz در شرایط یکسان، به مراتب سریعتر عمل میکند. - کش کردن رکوردهای DNS
درخواستهای DNS معمولاً در بستر UDP ارسال میشوند و سریع هستند، با این وجود میتوان رکوردهای DNS را کش کرد تا از درخواستهای DNS تکراری قبل از هر درخواست HTTP جلوگیری شود. - انتخاب سرور سریع
اگر از سرورهای مختلفی برای Load balancing و یا برای سرویس CDN استفاده شده است، با انتخاب سریعترین سرور میتوان به حمله سرعت بخشید. - تغییر پروتکل یا شمارهی پورت
اگر وب اپلیکیشن هدف با استفاده از هر دو پروتکل HTTP و HTTPS قابل دسترسی باشد، در شرایط برابر و در صورتی که رفتار نودهای موجود در مسیر نسبت به این دو یکسان باشد، استفاده از پروتکل HTTP لزوماً سریعتر خواهد بود. معمولاً رفتار سرورهای واسط در مورد این دو پروتکل متفاوت است و حتی ممکن است این رفتار در مورد پورتهای مختلف (مثلاً 80 و 443) نیز فرق داشته باشد. بنابراین، بدون بررسی نمیتوان گفت که استفاده از کدام پروتکل یا پورت برای اتصال به سرور هدف سریعتر خواهد بود. میتوان با بررسی و انتخاب سریعترین گزینه، به حمله سرعت بخشید. - استفاده از متد HEAD
متد HEAD مشابه متد GET است، با این تفاوت که با درخواست HEAD صرفاً هدرهای پاسخ دریافت شده و از بدنهی آن صرفنظر می شود. اگر معیار مقایسه کد وضعیت یا هدرهای پاسخ است، میتوان از این روش استفاده کرد. به عنوان مثال، اگر یک وبسرور برای آدرسهای ناموجود با کد وضعیت 404 و برای آدرسهای موجود با سایر کدها پاسخ دهد، برای بررسی موجودیت آدرسها میتوان از این متد استفاده کرد. - دور زدن محدودیت بر اساس IP Address
برخی هدرهای HTTP که در Forwarding درخواست بین سرورها کاربرد دارند، برای انتقال آدرس IP کاربر استفاده میشوند. موارد زیر برخی از این هدرها هستند:X-Originating-IP: IPAddress
X-Forwarded-For: IPAddress
X-Remote-IP: IPAddress
X-Remote-Addr: IPAddress
X-Client-IP: IPAddress
Client-IP: IPAddress
X-Real-IP: IPAddress
X-ProxyUser-Ip: IPAddress
اگر محدودیت تعداد درخواست بر اساس آدرس IP در لایهی 7 اعمال شده باشد، در صورتی که امکان بازنویسی این هدرها وجود داشته باشد و یا این هدرها به شکل نادرستی پردازش شوند، امکان جعل آدرس IP وجود دارد (IP Address Spoofing). همچنین، ممکن است از جعل آدرس IP برای دسترسی غیرمجاز استفاده شود. مثلاً در آسیبپذیری CVE-2019-9733 با استفاده از هدر:X-Forwarded-For: 127.0.0.1
برای جعل آدرس IP به آدرس محلی، پسورد حساب کاربری ادمین در وباپلیکیشن JFrog Artifactory تغییر داده میشد. روش دیگر، استفاده از تعداد زیاد آدرس IP برای بی اثر کردن محدودیت است. برخی سرویسهای ابری مثل Amazon AWS امکان تغییر متناوب آدرس IP برای درخواستها را فراهم میکنند. قبلاً برای دور زدن احراز هویت در اینستاگرام از این روش استفاده شده است. در صفحهی زیر میتوانید اطلاعات بیشتری دربارهی این موضوع به دست آورید:
هک حسابهای اینستاگرام در ۱۰ دقیقه
افزونهی IP Rotate در نرمافزار Burp Suite برای استفاده از این روش مفید است. همچنین، باتنت (Botnet) کاربرد مشابهی را برای مجرمان سایبری دارد.
- HTTP pipelining
درخواستهای HTTP (تا نسخهی 2) از طریق پروتکل TCP انجام میشوند. در روش معمول، ابتدا یک درخواست ارسال شده و پس از انتظار برای دریافت پاسخ آن، درخواست های بعدی ارسال می شوند (تصویر سمت چپ). در HTTP/1.1 روش HTTP pipelining تعریف شدهاست. در این روش، درخواستهای متعدد پشت سر هم و بدون وقفه ارسال میشوند و سپس، پاسخ ها به ترتیب درخواستها دریافت میشوند. (اولین پاسخ مربوط به اولین درخواست، FIFO)استفاده از این روش ممکن است سرعت را افزایش دهد. در HTTP/2.0، روش pipelining حذف و با HTTP multiplexing جایگزین شده است. با توجه به بالا بودن نسبت تعداد درخواستها به زمان، این روش برای بررسی یا اکسپلویت Race Condition نیز مناسب است. همچنین، ممکن است با استفاده از HTTP pipelining، فایروال وباپلیکیشن (WAF) را دور زد. برای اطلاعات بیشتر در این مورد، میتوانید به این ارائه مراجعه کنید.
مقایسه درخواست های HTTP با pipelining و بدون آن - فشردهسازی
در پروتکل HTTP، امکان توافق سرور و کلاینت برای استفاده از یک الگوریتم فشردهسازی برای کاهش حجم داده و افزایش سرعت انتقال وجود دارد. در مثال زیر مشخص است که اندازهی بدنهی پاسخ سرور با استفاده از الگوریتم فشردهسازی gzip بیش از 70 درصد کاهش یافته است:

ختم کلام
در نهایت، امیدواریم که از این مطلب لذت برده باشید و مفید واقع شود. 🙂
حوصله و پشتکارتون واقعا قابل تحسینه اینک ادم بشینه اونهمه توکن رو چک کنه ببینه چی توشون متشابهه واقعا دمتون گرم
چقدر عالی که جایزه بهتون دادن من خیلی باگ های Critical جاهای بزرگترو گزارش دادم متاسفانه هیچ جایزه ای ندادن 🙂
انگار فقط شما موفق بودین تو دریافت جایزه
فقط در جریان هم باشید که بهترین ها هم هستن متاسفانه شکست خوردن در دریافت جایزه و بیخیال شدن?
بسیار عالی، لذت بردم و مفید بود
فوقالعاده بود!
متشکر
عالی
لذت بردم
ممنون
حرفی نیست , هالی
چرا و به چه دلیلی باید متن رمزشدهی کد رو از کاربر بگیره؟ قاعدتا این کد باید سمت کارگزار ذخیره بشه و کد دریافتی از کاربر باهاش تطبیق داده بشه
من زیاد این مدل رو میبینیم توی کتابها امن خیلی بش اشاره شده
واقعا لذت بردم
مقاله خیلی کاملی بود همه چی را خوب توضیح دادید و خیلی برای من مفید بود چیز های خیلی خوبی یاد گرفتم تجربه ای که معلوم نیست با چقدر کار بدست اومده در چند دقیقه با کاربرا انتقال دادید ممنون از شما و دمتون گرم
خواهش میکنم مرسی از نظر
عالی بود واقعا
میخواستم به عنوان نویسنده افتخاری یک رایت آپ بنویسم لطفا راهنمایی کنید.
به من تلگرام پیغام بده
[…] کافهبازار. دو پست قبلی رو میتونید از اینجا و اینجا بخونید. این پست راجع به آسیبپذیری هست که سال پیش بر […]